-
(4) 프로세스 관리, (5) CPU 스케줄링, (6) Process Syncronization운영체제 2024. 11. 2. 21:40
참고: 이화여대 반효경 교수님 운영체제 강의
http://www.kocw.net/home/search/kemView.do?kemId=1046323
프로세스 생성
- 부모 프로세스가 자식 프로세스를 복제 생성(Copy-on-Write, COW)하며, 트리(계층 구조)로 형성됨
- 부모와 자식이 자원을 공유할 수도, 공유하지 않을 수도 있음(경제 관계)
- 부모와 자식은 공존하며 수행되는 모델이며, 자식이 종료(terminate)될 때까지 부모가 기다리는(wait) 모델도 있음
주소 공간
- 자식은 부모의 주소공간을 복사(fork 시스템 콜)하고, 그 공간에 새 프로그램을 올림(exec 시스템 콜)
프로세스 종료
- 프로세스가 마지막 명령을 수행한 후, 운영체제에게 이를 알려줌(exit)
- 프로세스의 각종 자원들이 운영체제에게 반납됨
- 부모 프로세스가 자식의 수행을 종료시키고(abort), 이후 부모가 종료(exit)됨. -> 단계적인 종료
독립적 프로세스: 프로세스는 각자 주소 공간을 가지고 작업하므로 원칙적으로 다른 프로세스에 영향을 미치지 않음
협력 프로세스: 프로세스 협력 메커니즘을 통해 다른 프로세스에 영향을 미칠 수 있음
프로세스 간 협력 메커니즘(IPC: Interprocess Communication)
① message passing: 운영체제 커널을 통해 메시지 전달, 공유 변수를 사용하지 않고 통신함
- 직접 통신(통신하려는 프로세스 이름을 명시), 간접 통신(mailbox, 혹은 port를 통해 전달)
② shared memory: 서로 다른 프로세스 간에도 일부 주소 공간을 공유
CPU 스케줄링
CPU 스케줄러(운영체제 중 CPU를 스케줄링하는 코드): Ready 상태의 프로세스 중 이번에 CPU 줄 프로세스를 고름
디스패처 Dispatcher: CPU의 제어권을 선택된 프로세스에게 직접 넘긴다 (즉, Context Switch=문맥 교환을 담당)
CPU 스케줄링이 필요한 경우는 프로세스에게 다음과 같은 상태 변화가 있을 때이다
① Running -> Blocked (입출력 요청하는 시스템 콜)
② Running -> Ready (할당 시간 만료로 timer interrupt)
③ Blocked -> Ready (입출력 완료 후 interrupt)
④ Terminate
①, ④ nonpreemptive (=비선점형, 강제로 빼앗지 않고 자진 반납)
다른 모든 스케줄링은 preemptive(=선점형, 강제로 빼앗음)
성능 척도
(1) 이용률 CPU utilization: 가능한 일을 많이 시켜
(2) 처리량 Throughput: 주어진 시간 내에 얼마나 많은 일을 하는지
(3) 소요시간 Turnaround time: CPU를 쥐고 있는 시간
(4) 대기시간 Waiting time: CPU를 받기까지 기다리는 시간
(5) 응답 시간 Response time: Ready Queue에 들어와서 처음 CPU를 얻기까지 걸린 최초의 시간
스케줄링 기법
FCFS (First-Come First-Served, 선입선출): 프로세스의 도착 순서에 따라 선입선출 방식으로 CPU를 할당함
만약 긴 시간을 점유해야 하는 프로세스가 먼저 도착했을 경우 매우 비효율적이기 때문에 Convoy effect(Ready Queue에서 너무 오래 기다려야 함)가 일어남
SJF (Shortest-Job-Fisrt, 짧은 시간 우선): CPU burst 시간이 가장 짧은 프로세스에 먼저 CPU를 할당함
주어진 프로세스들에 대해 최소 평균 waiting time을 보장하므로 효율적임
① Nonpreemptive: 일단 CPU를 잡으면 이번 CPU burst가 완료될 때까지 CPU를 선점(preemptive) 당하지 않음
② Preemptive: 현재 수행 중인 프로세스의 남은 burst time보다 더 짧은 CPU burst 시간을 가지는 새로운 프로세스가 도착하면 CPU를 빼앗김 -> 이 방법을 SRTF(Shortest-Remaining-Time-First)라고 부름
우선순위 스케줄링 Priority Scheduling: 각 프로세스에 우선순위를 부여하고, 높은 우선순위대로 CPU 할당함
① Nonpreemptive: 일단 CPU를 잡으면 이번 CPU burst가 완료될 때까지 CPU를 선점(preemptive) 당하지 않음
② Preemptive: 현재 프로세스의 priority보다 더 높은 priority의 프로세스가 올 경우 CPU를 빼앗김
기아 현상 Starvation: SJF, Priority Scheduling의 문제점으로 priority가 낮은 프로세스는 영원히 기다려야 함
노화 Aging: 기다린 시간이 오래되면 priority를 증가시켜 Starvation을 막음
Round Robin RR: 각 프로세스는 동일한 크기의 할당 시간을 가짐
할당 시간이 지나면 프로세스는 선점(preemptive)당하고, Ready Queue의 제일 뒤로 가 다시 줄을 선다.
단점: Q가 클 경우 FCFS가 됨, Q가 작을 경우 문맥 교환 오버헤드가 커짐
Multilevel Queue: Ready Queue를 우선순위에 따라 여러 개 만듦
- foreground(interactive, RR), background(batch - no human interaction, FCFS)
Multilevel Feedback Queue: Ready Queue를 여러 개 만들면서 우선순위는 바뀔 수 있음
로컬 스케줄링: 유저 레벨 쓰레드의 경우, 사용자 수준의 쓰레드 라이브러리에 의해 어떤 쓰레드를 스케줄할지 결정
글로벌 스케줄링: 커널 리벨 쓰레드의 경우 일반 프로세스와 마찬가지로 커널의 단기 스케줄러가 어떤 쓰레드를 스케줄할지 결정
알고리즘 평가 기준
Queueing Models: 확률 분포로 주어지는 arrival rate와 service rate 등을 통해 각종 퍼포먼스 인덱스 값을 계산
Implementation(구현) & Measurement(성능 측정): 실제 시스템에 알고리즘을 구현하여 실제 작업에 대해서 성능을 측정 비교
Simulation(모의 실험): 알고리즘을 모의 프로그램으로 작성 후, trace를 입력으로 하여 결과 비교
Process Syncronization
race condition(동시 접근): 여러 프로세스들이 동시에 공유 데이터를 접근하는 상황
공유 데이터의 동시 접근은 데이터의 불일치 문제를 발생시킬 수 있음.
일관성 유지를 위해서는 협력 프로세스 간의 실행 순서를 정해주는 동기화 메커니즘이 필요함 (Syncronization)
각 프로세스의 code segment에는 공유 데이터를 접근하는 코드인 critical section이 존재함
하나의 프로세스가 critical section에 있을 때, 다른 프로세스는 critical section에 들어갈 수 없어야 함
동기화 프로그램적 해결법의 충족 조건
상호 배제 Mutual Exclusion: 프로세스가 critical section 부분을 수행 중이면, 다른 프로세스는 들어갈 수 없음
진행 Progress: 아무도 critical section에 있지 않은 상태에서 critical section에 들어가고자 하는 프로세스가 있으면 들어가게 해주어야 함
유한 대기 Bounded Waiting 프로세스가 critical section에 들어가려고 요청한 후부터 그 요청이 허용될 때까지 다른 프로세스들이 critical section에 들어가는 횟수에 한계가 있어야 함 (=no starvation)
피터슨의 알고리즘 Peterson's Algorithm

깃발이 내려가 있고, 내 턴일 때 critical section에 들어갈 수 있음.
-> 상호 배제, 진행, 유한 대기 조건을 충족시킴
Spinlock(Busy Waiting)의 문제점
Spinlock(=Busy Waiting): 계속 CPU와 메모리를 쓰면서 Wait
Semaphores: 앞의 방식들을 추상화시킴, 추상 자료형
P(S) 연산: 공유 데이터를 획득하는 과정, V(S) 연산: 자원을 반납하는 과정
문제점: 코딩하기 힘들고, 정확성 입증이 어려우며 한 번의 실수가 모든 시스템에 치명적 영향을 준다
Monitor: 동시 수행 중인 프로세스 사이에서 추상 데이터 타입의 안전한 공유를 보장하기 위한 고레벨 동기화 구조체
모니터 내에서는 한 번에 하나의 프로세스만이 활동 가능함. 프로그래머가 동기화 제약 조건을 명시적으로 코딩할 필요가 없음!
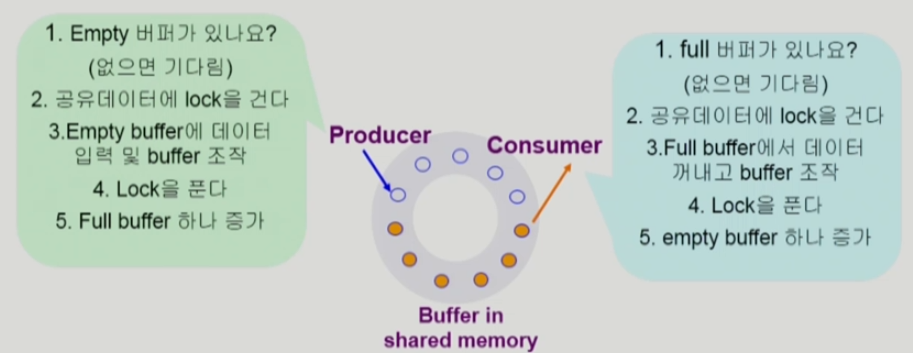
유한한 버퍼 문제 Bounded-Buffer Problem
Readers-Writers Problem
- 한 process가 DB에 write 중일 때 다른 process가 접근하면 안 되지만, read는 동시에 여럿이 해도 됨
solution
1. Writer가 DB에 접근 허가를 아직 얻기 전이면, 모든 대기 중인 Reader들을 다 DB에 접근하게 해준다
2. Writer은 대기 중인 Reader가 하나도 없을 때 DB 접근이 허용된다
3. 일단 Writer가 DB에 접근 중이면 Reader들은 접근이 금지된다
4. Writer가 DB에서 빠져나가야만 Reader의 접근이 허용된다
Deadlock: 둘 이상의 프로세스가 서로 상대방에 의해 충족될 수 있는 event를 무한히 기다리는 현상
Starvation: 프로세스가 suspend된 이유에 해당하는 세마포어 큐에서 빠져나갈 수 없는 현상
'운영체제' 카테고리의 다른 글
(10) 파일 시스템, (11) 디스크 관리 및 스케줄링 (1) 2024.11.25 (7) 데드락, (8) 메모리 관리, (9) 가상 메모리 (0) 2024.11.18 (1) 운영체제란 무엇인가, (2) 시스템 구조와 프로그램 실행, (3) 프로세스 (0) 2024.10.30